



The very first task in any data analysis workflow is simply reading the data, and this absolutely must be done quickly and efficiently so the more interesting work can begin. Across many industries and domains, the CSV file format is king for storing and sharing tabular data. Loading CSVs fast and robustly is crucial, and it must scale well across a wide variety of file sizes, data types, and shapes. This post compares the performance for reading 8 different real-world datasets across three different CSV parsers: R’s fread, Pandas’ read_csv, and Julia’s CSV.jl. Each of these was chosen as the “best in class” CSV parser in each R, Python and Julia, respectively.
All three tools have robust support for loading a wide variety of data types with potentially missing values, but only fread (R) and CSV.jl (Julia) support multithreading—Pandas only supports single threaded CSV loading. Julia’s CSV.jl is further unique in that it is the only tool that is fully implemented in its higher-level language rather than being implemented in C and wrapped from R / Python. (Pandas does have a slightly more capable Python-native parser, it is significantly slower and nearly all uses of read_csv default to the C engine.) As such, the CSV.jl benchmarks here not only represent the speed of loading data in Julia, but are also indicative of the sorts of performance that’s possible in the subsequent Julia code used in the analysis.
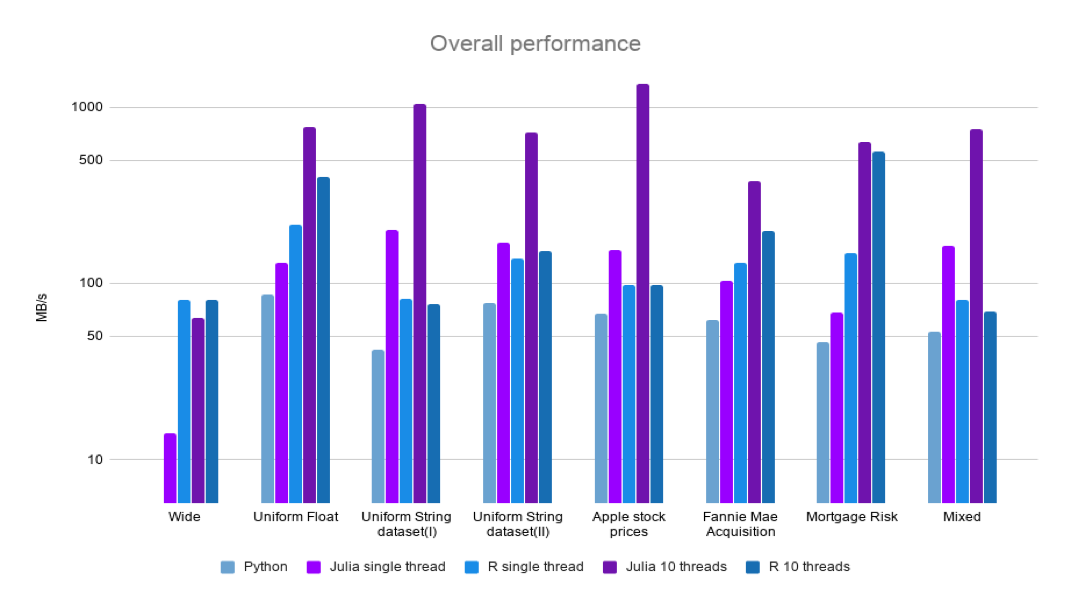
The following benchmarks show that Julia’s CSV.jl is 1.5 to 5 times faster than Pandas even on a single core; with multithreading enabled, it is as fast or faster than R’s read_csv. The tools used for benchmarking were BenchmarkTools.jl for Julia, microbenchmark for R, and timeit for Python.
Homogenous data
Let’s start with some homogeneous datasets i.e. datasets which have the same kind of data in all columns. The datasets in this section, apart from stock price dataset, are derived from this benchmark site. The performance metric is the time taken to load a dataset as the number of threads is increased from 1 to 20. Since Pandas does not support multi-threading, single threaded speed is reported across the board for all core counts.
Performance on Homogenous Datasets:
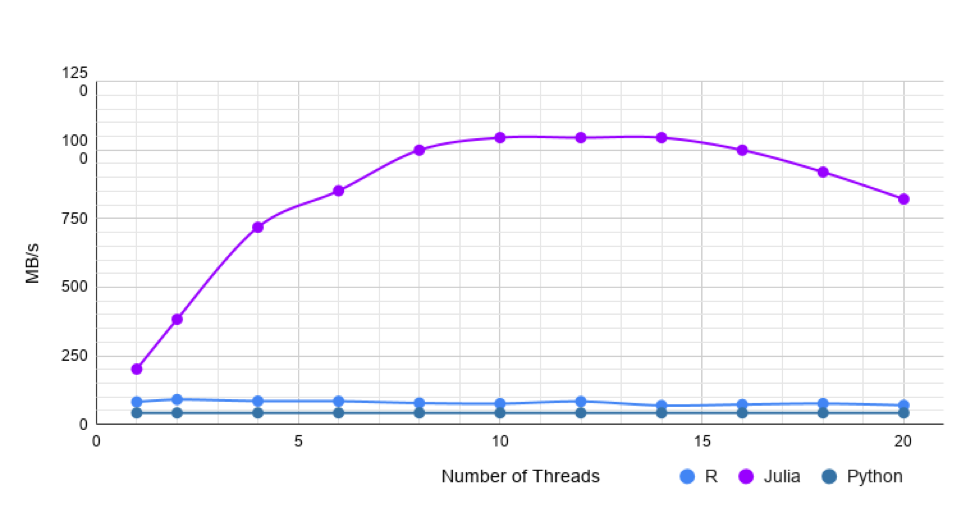
Uniform Float dataset: The first dataset contains float values arranged in 1 Million rows and 20 columns. Pandas takes 232 milliseconds to load this file. Single threaded data.table is 1.6 times faster than CSV.jl. With Multithreading, CSV.jl is at its best, more than double the speed of data.table. CSV.jl is 1.5 times faster than Pandas without multithreading, and about 11 times faster with.
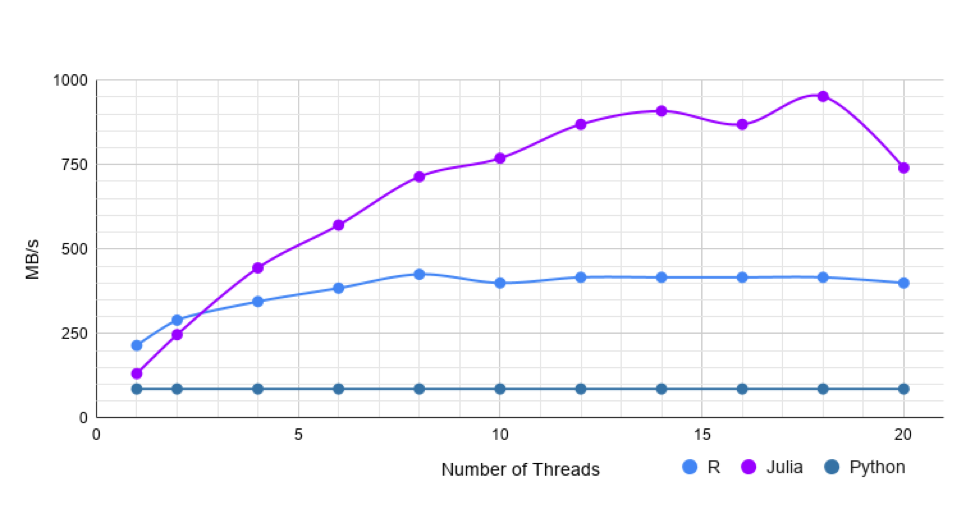
This dataset contains 50 million rows and 5 columns, and is 2.5GB. The rows are open, high, low, and close prices for AAPL stock. The four columns with prices are float values, and there is a date column.
The single threaded CSV.jl is about 1.5 times faster than R’s fread from data.table. With multithreading CSV.jl is about 22 times faster! Pandas’ read_csv takes 34s to read, this is slower than both R and Julia.
Performance on Heterogeneous Datasets
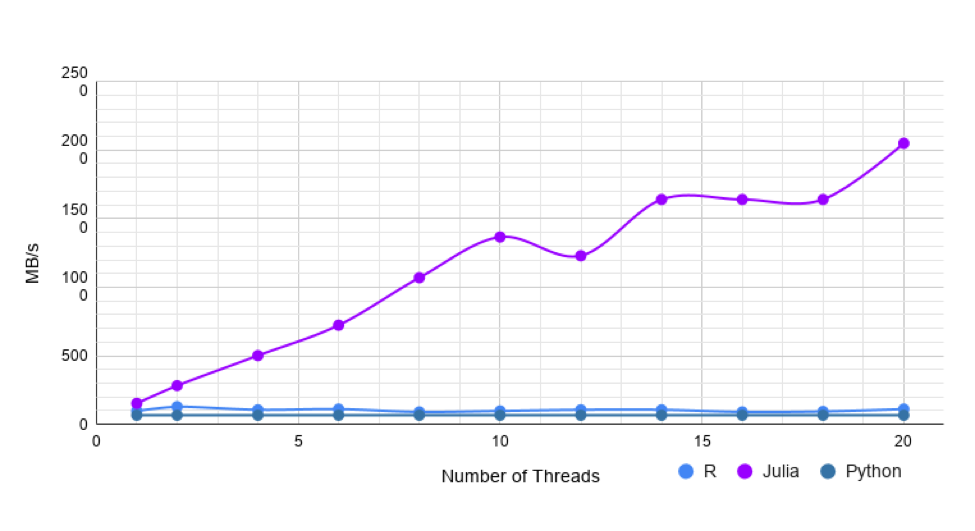
Mixed dataset: This dataset has 10k rows and 200 columns. The columns contain, String, Float, DateTime, and missing values. Pandas takes about 400 milliseconds to load this dataset. Without threading, CSV.jl is 2 times faster than R, and is about 10 times faster with 10 threads.
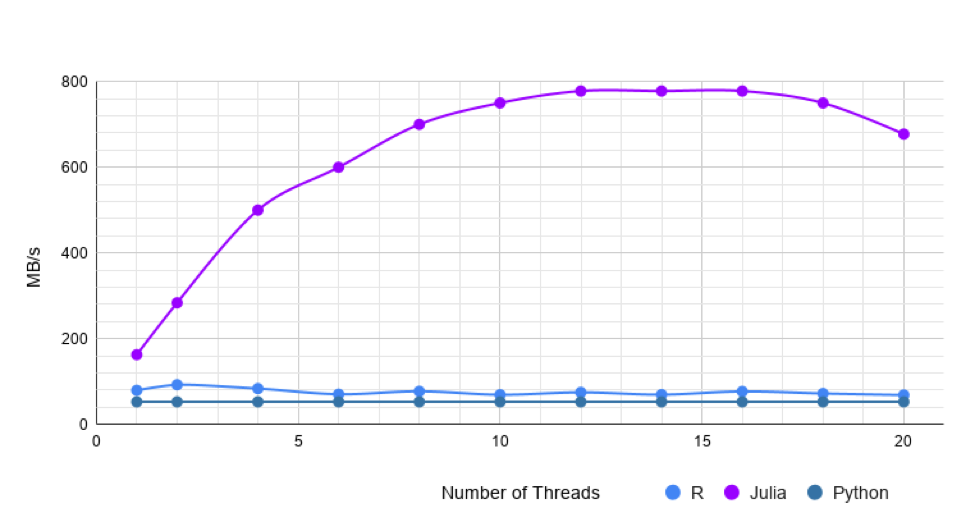
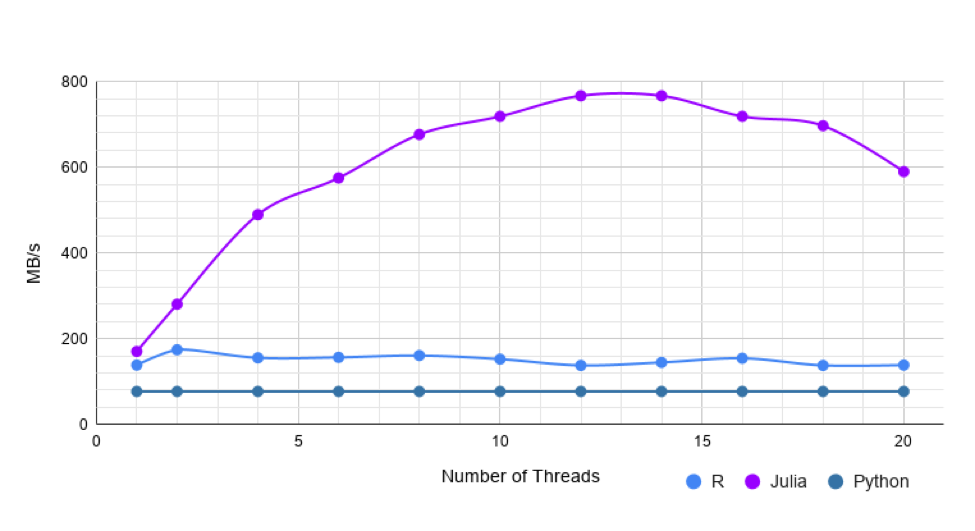
Now, let’s look at a wider dataset. This mortgage risk dataset from Kaggle is a mixed type dataset, with 356k rows and 2190 columns. The columns are heterogeneous and have values of types String, Int, Float, Missing. Pandas takes 119s to read in this dataset. Single threaded fread is about twice faster than CSV.jl. However, with more threads Julia is either as fast or slightly faster than R.
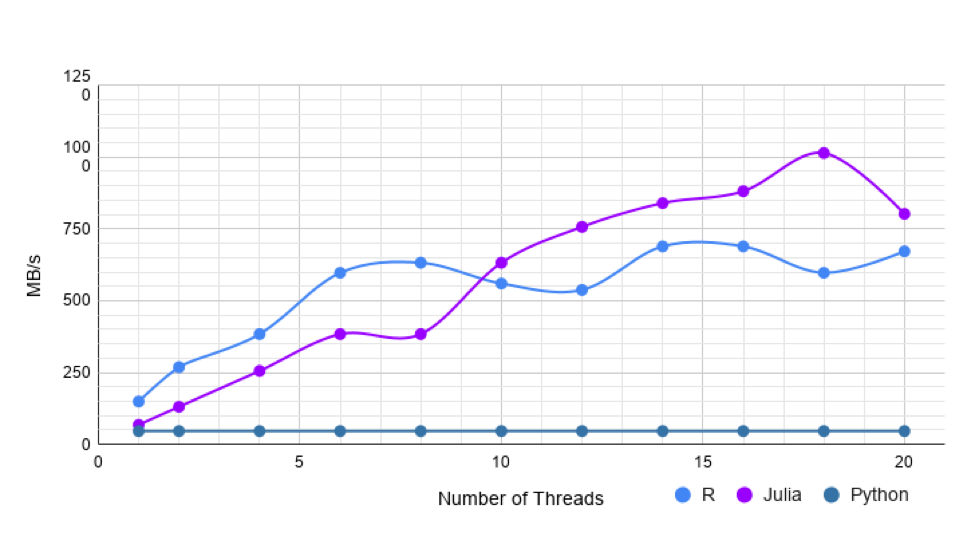
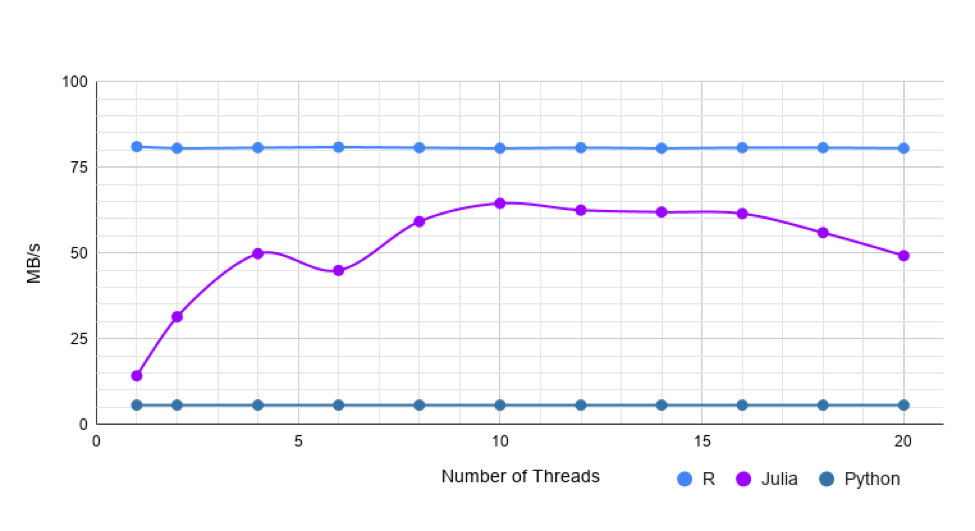
Single threaded data.table is 1.25 times faster than CSV.jl. But, the performance of CSV.jl keeps increasing with more threads. CSV.jl gets about 4 times faster with multi-threading.
System Info: The specs of the system on which the benchmarking was performed are as below
$ lsb_release -a
No LSB modules are available.
Distributor ID: Ubuntu
Description: Ubuntu 18.04.4 LTS
Release: 18.04
Codename: bionic$ uname -a
Linux antarctic 5.6.0-custom+ #1 SMP Mon Apr 6 00:47:33 EDT 2020 x86_64 x86_64 x86_64 GNU/Linux$ lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 40
On-line CPU(s) list: 0-39
Thread(s) per core: 2
Core(s) per socket: 10
Socket(s): 2
NUMA node(s): 2
Vendor ID: GenuineIntel
CPU family: 6
Model: 85
Model name: Intel(R) Xeon(R) Silver 4114 CPU @ 2.20GHz
Stepping: 4
CPU MHz: 800.225
CPU max MHz: 3000.0000
CPU min MHz: 800.0000
BogoMIPS: 4400.00
Virtualization: VT-x
L1d cache: 32K
L1i cache: 32K
L2 cache: 1024K
L3 cache: 14080K
NUMA node0 CPU(s): 0-9,20-29
NUMA node1 CPU(s): 10-19,30-39$ free -h
total used free shared buff/cache available
Mem: 62G 3.3G 6.3G 352K 52G 58G
Swap: 59G 3.2G 56G